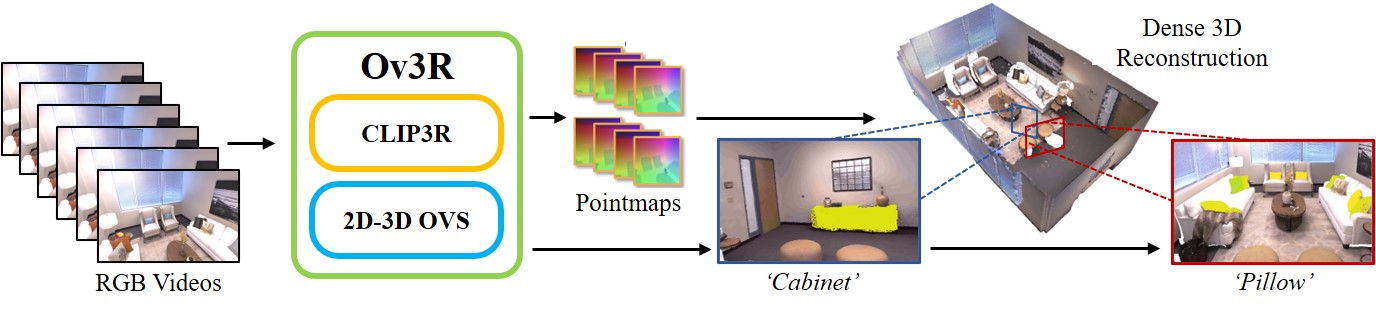
Pipeline of Ov3R. Ov3R is an Open-Vocabulary Semantic 3D Reconstruction Framework. It consists of two novel feed-forward modules, CLIP3R and 2D–3D OVS, and excels in both 3D reconstruction and open-vocabulary 3D semantic segmentation.
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI.
The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips alongside object-level semantics; and 2D–3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment.
Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation — marking a step forward toward real-time, semantics-aware Spatial AI.
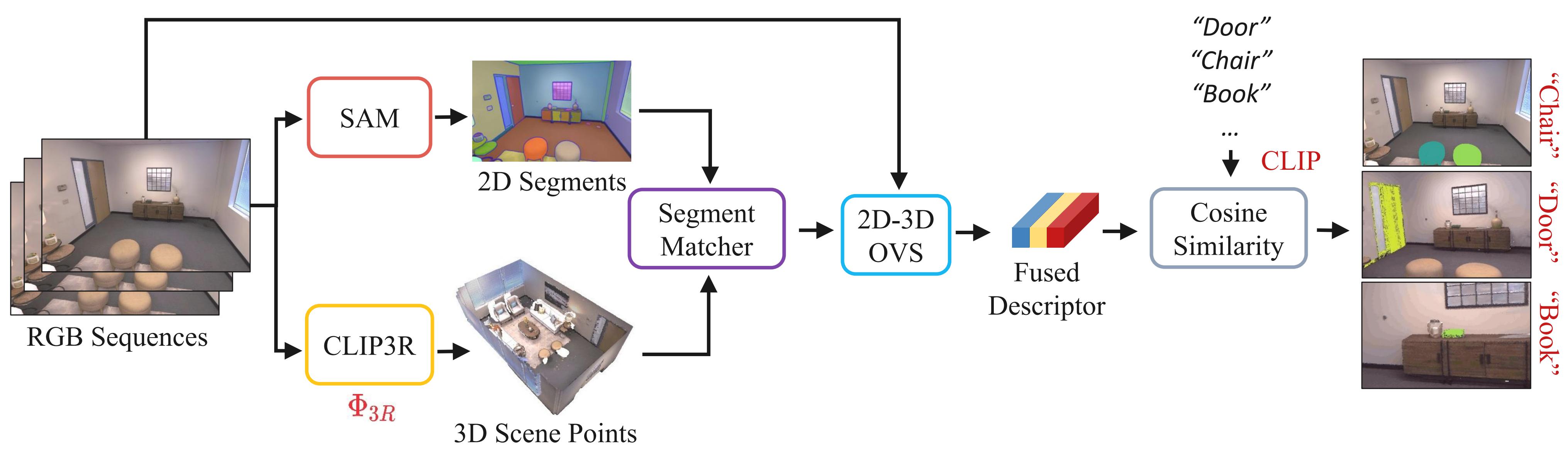
Annotations: Given RGB-only videos, we first apply CLIP3R to produce scene points while SAM predicts 2D segments. Each 2D segment is matched to its corresponding 3D points to obtain 3D semantics. Next, the 2D-3D OVS extracts the fused 2D-3D descriptor to compute the cosine similarity with the text embeddings corresponding to a set of semantic classes.

Annotations: We present open-vocabulary segmentation results of several different objects. Ov3R demonstrates accurate segmentations for diverse situations, e.g. multiple objects (pillows, chairs), small objects (vases), and large objects (tables).

Annotations: For each scene, we provide ground truth pointmaps as references, and compare our reconstructed indoor scenes against SLAM3R and Spann3R. Ov3R presents stronger performance on geometry consistency and accuracy, while SLAM3R outputs misaligned recosntructions and Spann3R predicts very sparse pointmaps.
Our final reconstruction and segmentation results are available now. You can find it in the above Results button or you can download it through Google Drive.
There's a lot of excellent work that was introduced around the same time as ours.
DINO-SLAM: DINO-informed RGB-D SLAM for Neural Implicit and Explicit Representations provides two foundational paradigms for NeRF and 3DGS SLAM systems integrating geometry-aware DINO features.
HS-SLAM: Hybrid Representation with Structural Supervision for Improved Dense SLAM introduce HS-SLAM to enhance scene representations, capture structural information, and maintain global consistency.
How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: a Survey provides the first comprehensive survey of SLAM progress through the lens of the latest advancements in radiance fields (NeRF and 3DGS).
Go-SLAM introduces a deep-learning-based dense visual SLAM framework that achieves real-time global optimization of poses and 3D reconstruction.
@article{gong2025ov3r,
title={Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos},
author={Gong, Ziren and Li, Xiaohan and Tosi, Fabio and Han, Jiawei and Mattoccia, Stefano and Cai, Jianfei and Poggi, Matteo},
journal={arXiv preprint arXiv:2507.22052},
year={2025}
}